How I built the fastest no-code blog on the internet?
August 14, 2025

August 14, 2025
Ever since my Writee days, I have been fascinated with SEO. In fact, a friend keeps joking how I consider my biggest achievement with Writee to not be building the company but getting listed on Google. Building Writee’s SEO invariably forced me to understand how blogs work - after all blogs are the bedrock of almost all SEO effort. This led me to something prize a lot - my personal blog where I am writing this. My personal blog is my personal corner in this vast, invisible internet. This is where I am rawest on the internet, where you can see me for who I am and not who I project myself to be.
As a technically-fascinated individual (I am not “technical” person or a “technically-inclined” - it’s more of a fascination), I found myself stuck with the traditional blogging tools on the internet. Setting up headless CMS’, getting your technical SEO on-point and getting everything blazing fast was always a pain. Hours were lost managing headless CMS configurations, manually setting up JSON+LD schemas, and fighting with next.config.js just to get images to load correctly.
There were alternatives to this. Superblog - which is an everything managed, blogging CMS is a fantastic, turnkey solution for those who want a completely hands-off experience and are willing to pay for the convenience. But as an early-stage founder/student combo watching every penny, Superblog was too expensive for an important albeit simple thing. I wanted to capture that same magic—the everything-just-works feeling—but on my own terms. That’s how NotoStack was born.
The first step to building any product is deciding on some basic truths about your product. In my case it was figuring out the following:
astro.js which I have been using since it’s initial v1 launch. It was perfect for this use case.With the guiding principles of my product in place, it was time to start architecting and then developing the product. My typical approach with architecting is to design for shortest dev time. I want to get my products to market as fast as possible and figure out if it deserves more complicated system designs. I do not typically go for production tools like Kafka Queues or massive micro-service architectures to cut down dev time. This is your typical build to break start-up mindset which destroyed 2 weeks worth of work. I ended up designing an system which was too simple for it’s own good. Every technical problems need to be given due respect in terms of design. Not everything can be solved with a “hello world” response on an express API call. I learnt this the hard way. Here’s my initial design.
My first architecture was a linear, pragmatic, and ultimately, deeply flawed solution. It was a single, perpetually running Node.js process I called the Build-Deploy Engine. My thinking was simple: get the job done, get it done right. The core idea revolved around using a MongoDB collection as a rudimentary job queue. When a user updated their Notion database, the perpetual node.js process would pick it up through an infinite loop that checked every user’s Notion DB’s updated at time and added a new document into this Mongo queue. The monolithic Build-Deploy Engine would then pull the job and start its work.
It felt good. It felt productive. I had a system that, on paper, worked flawlessly:
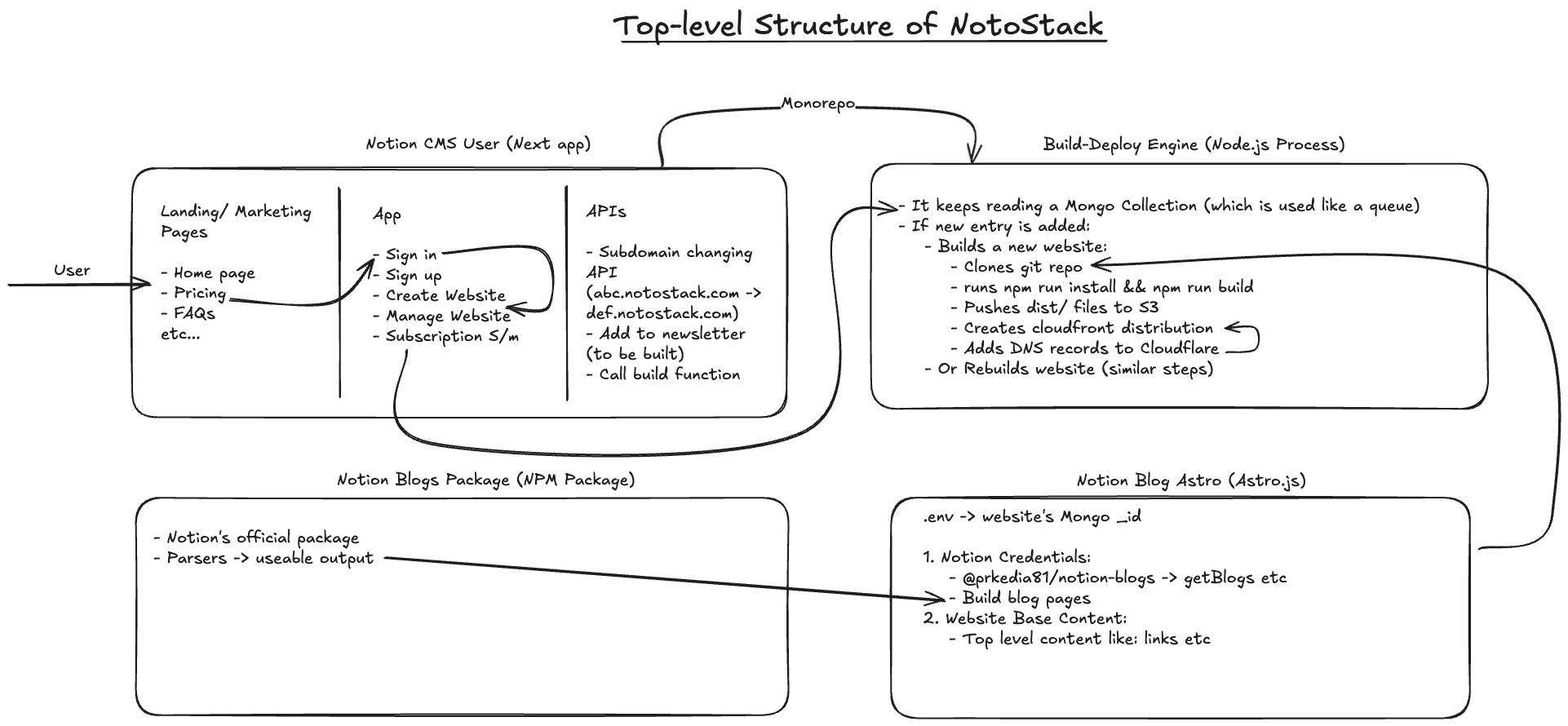
I was proud of this. It was a logical, well-documented system built with familiar tools. It was a straight line from A to B. But then I saw a single site build take a full 90 seconds. For one user, doesn’t matter. What if ten users hit "publish" at the exact same time? My single Node.js process, no matter how optimized, would become a serial bottleneck. It would process one job, then the next, then the next, creating a virtual line of frustrated writers staring at a "Deploying..." spinner. The tenth user might be waiting for 15 minutes. That’s an eternity. What if the engine crashed mid-build while running npm install for User #5? The job (the update) would be lost forever. The user would be left with a half-deployed website and no idea what went wrong.
My system was reactive, but it wasn't resilient. It was functional, but barely. I had the right blueprint, just that I was trying to build a skyscraper with tape and glue.
I spent an entire weekend staring at my code. Sunk cost is a powerful sedative, and I had invested weeks into my Build-Deploy Engine. It was my code but I knew it was a house built on a shaky foundation. My system was brittle, and I needed to make a fundamental ideological shift: from a synchronous, single-point-of-failure mindset to an asynchronous, distributed, and self-healing one.
This was the pivotal moment. This wasn't a refactor; it was a complete re-architecture of the platform's core. I had to throw away weeks of work and rebuild the entire deployment pipeline from the ground up. The new foundation would be built on two pillars of modern backend engineering: Redis for its raw, in-memory speed, and BullMQ for its powerful job queuing capabilities.
Why this specific combination? It was about choosing the absolute best tool for each specific job.
This decision to abandon Mongo for the queue and embrace the Redis/ BullMQ stack is an architectural decision that taught me more than a lot of the production-level code I have written. There is a reason somethings are done the way they are, give a technical problem it’s due respect and use the required tools for the job. The result was a system that wasn't just faster—it was smarter, more resilient, and ready to scale infinitely.
The new architecture is a game-changer. Gone is the single, overworked artisan. In its place is a meticulously designed, distributed factory floor. We now have a fleet of specialized, stateless "workers," all communicating through the lightning-fast, Redis-backed Bull-MQ message bus. The entire process is fully asynchronous and event-driven.
Here’s how the new, ridiculously fast workflow breaks down:
@prkedia81/notion-blogs NPM package, and runs the npm run build process. This worker is a memoryless automaton; it knows nothing of the previous job and retains no state. If it succeeds, great. If it fails for any reason, Bull-MQ's resilience kicks in. The job is gracefully re-queued and instantly picked up by another available worker. This provides fault tolerance on a massive scale.Why is this worker-based, distributed factory floor so much better?
Every great system has its secret weapon - a custom-built tool that solves a unique problem so elegantly that it becomes a competitive advantage. For NotoStack, that weapon is a small, unassuming NPM package I poured countless hours into: @prkedia81/notion-blogs
On the surface, its job sounds simple: get content from Notion. But anyone who has worked with the Notion API knows that "simple" is the last word to describe it.
The Notion API is an engineering marvel. It's incredibly powerful and flexible, but it doesn't give you a clean, blog-ready post. Instead, it gives you a box of beautiful, high-quality, but completely unusable, deeply nested JSON tree of "blocks." A single blog post isn't a flat file of HTML; it's a complex hierarchy of page properties, database relations, and an array of block objects—paragraphs, headings, images, code snippets, callouts, and more—each with its own unique structure and metadata.
My first builds directly tried to wrestle with this raw data. The build script became a tangled mess of if/else statements or switch cases, and recursive functions trying to parse this tree. It was slow, brittle, and a nightmare to debug. If Notion ever added a new block type, the entire script would break.
I realized I wasn't just fetching data; I was performing a complex data transformation. The build process didn't need a simple API client; it needed an expert translator. It needed a specialized tool that could take Notion's esoteric language and convert it into a simple, predictable format that a static site generator like Astro could understand instantly.
This realization led to the birth of @prkedia81/notion-blogs. This package is the Rosetta Stone of the NotoStack ecosystem.
Here’s what makes it so critical:
heading_2 block is and how to extract its text. It knows how to get the URL from an image block and the language from a code block. It takes that chaotic, nested structure and transforms it into a clean, flat array of objects like an output from a traditional CMS.getBlogPosts(). It receives a perfect, predictable array of content, ready to be rendered into HTML. This makes the build process faster, more reliable, and infinitely easier to maintain.Developing this package was a labor of love. It involved hours of poring over API documentation, writing tests for dozens of block types, and handling countless edge cases. But this investment created a core piece of intellectual property. @prkedia81/notion-blogs is the unsung hero of every single build. It's the specialized, hyper-efficient tool on our "distributed factory floor" that ensures the raw material (Notion content) is perfectly prepared before it even hits the main assembly line.
Achieving instantaneous speed required a tech stack where every component was obsessively chosen for performance.
@prkedia81/notion-blogs): My custom NPM package acts as a hyper-efficient translator. It converts Notion's complex, nested JSON data into a clean, build-ready format once, during the build process. This crucial step prevents the user's browser from ever having to do the heavy lifting.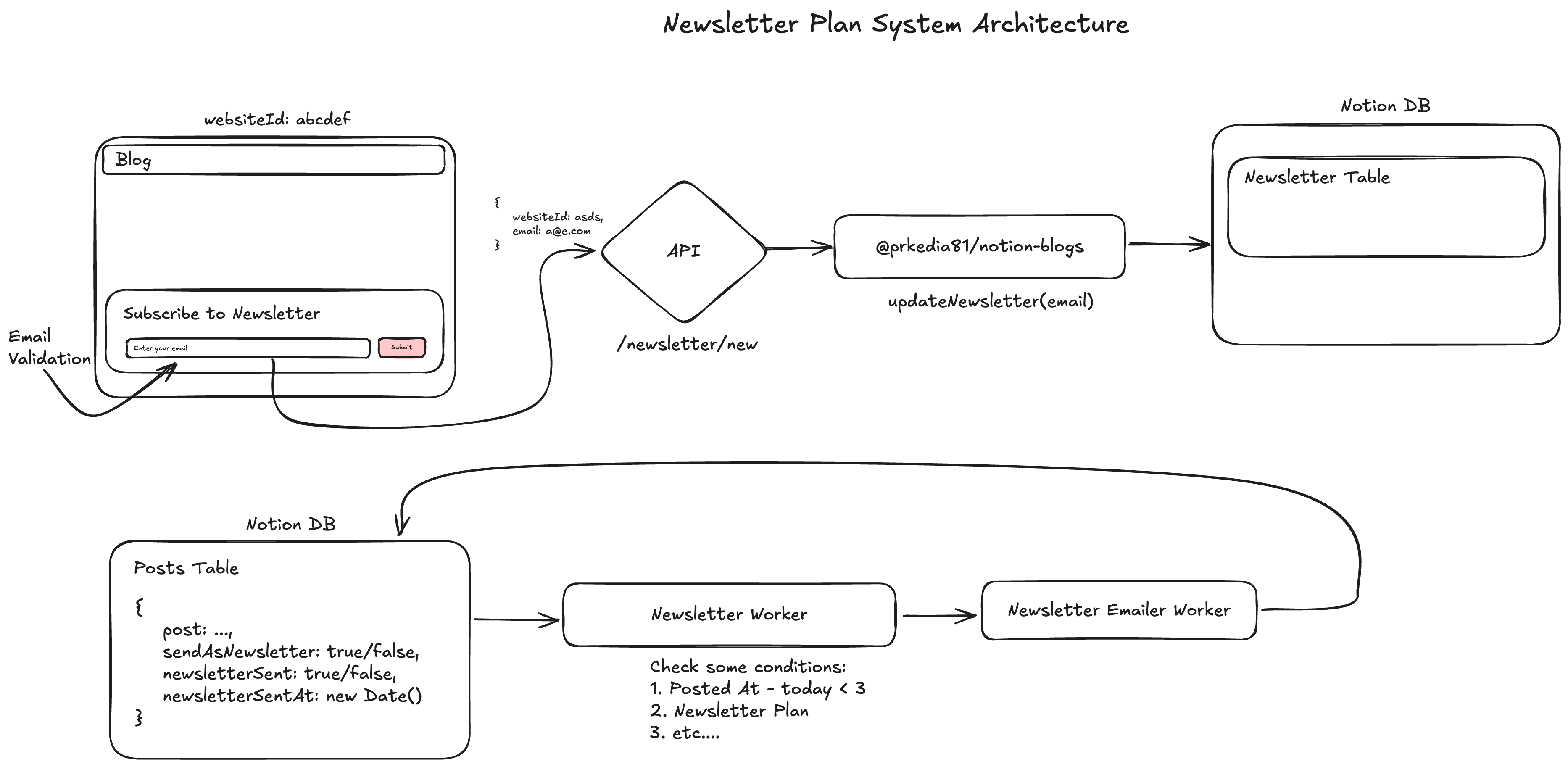
After all this work - the refactoring, the architectural debates, the obsessive tuning - I decided to deprecate the project. While the challenge was exhilarating, I realized that building and maintaining the platform itself wasn't what truly excited me. The real prize wasn't the final product, but the incredible learning journey I took to get there.
However, one crucial piece of NotoStack not only survived but has become a cornerstone of my development workflow: the @prkedia81/notion-blogs package. This little NPM package has become my personal lifesaver. Now, for every new project I build, adding a fast, SEO-optimized blog is no longer a chore. I just plug in the package, point it to a Notion database, and it just works. No more fighting with complicated CMSs; my entire content workflow for any idea now lives happily in Notion.
Ultimately, the most profound takeaway was the architectural one. My initial "build to break" mindset taught me a hard lesson: you must give a technical problem its due respect. Forcing a database to act as a queue was a mistake. Embracing the right tools for the job, like Redis and BullMQ, even though they added a bit of initial complexity, was the right call. It’s a philosophy I now carry into every project—sometimes, the right path isn't the simplest one, but the most robust. The NotoStack code may be gone, but the lessons and the tools it produced are here to stay.